ディープラーニングによるコミュニケーション技術の進化|松尾 豊 氏(東京大学大学院 工学系研究科・教授)
Communication Tech Conference 2019 講演レポート
投稿日:2020年1月6日 | 更新日:2025年2月26日

本日は、「ディープラーニングによるコミュニケーション技術の進化」ということで、お話させていただきます。
昨今、注目されるディープラーニングの技術が、今後どういう風な進展をしてくるのか非常に重要です。その先には、言葉の意味理解とコミュニケーションの大きな変化が起こると思っています。
これからどのような技術の進化が起こっていくのか、それが言葉やコミュニケーションとどういった関係があるのかをお話ししていきたいと思います。技術の展望になりますので少し分かりにくいところがあるかもしれませんが、非常に重要だと思われる点です。
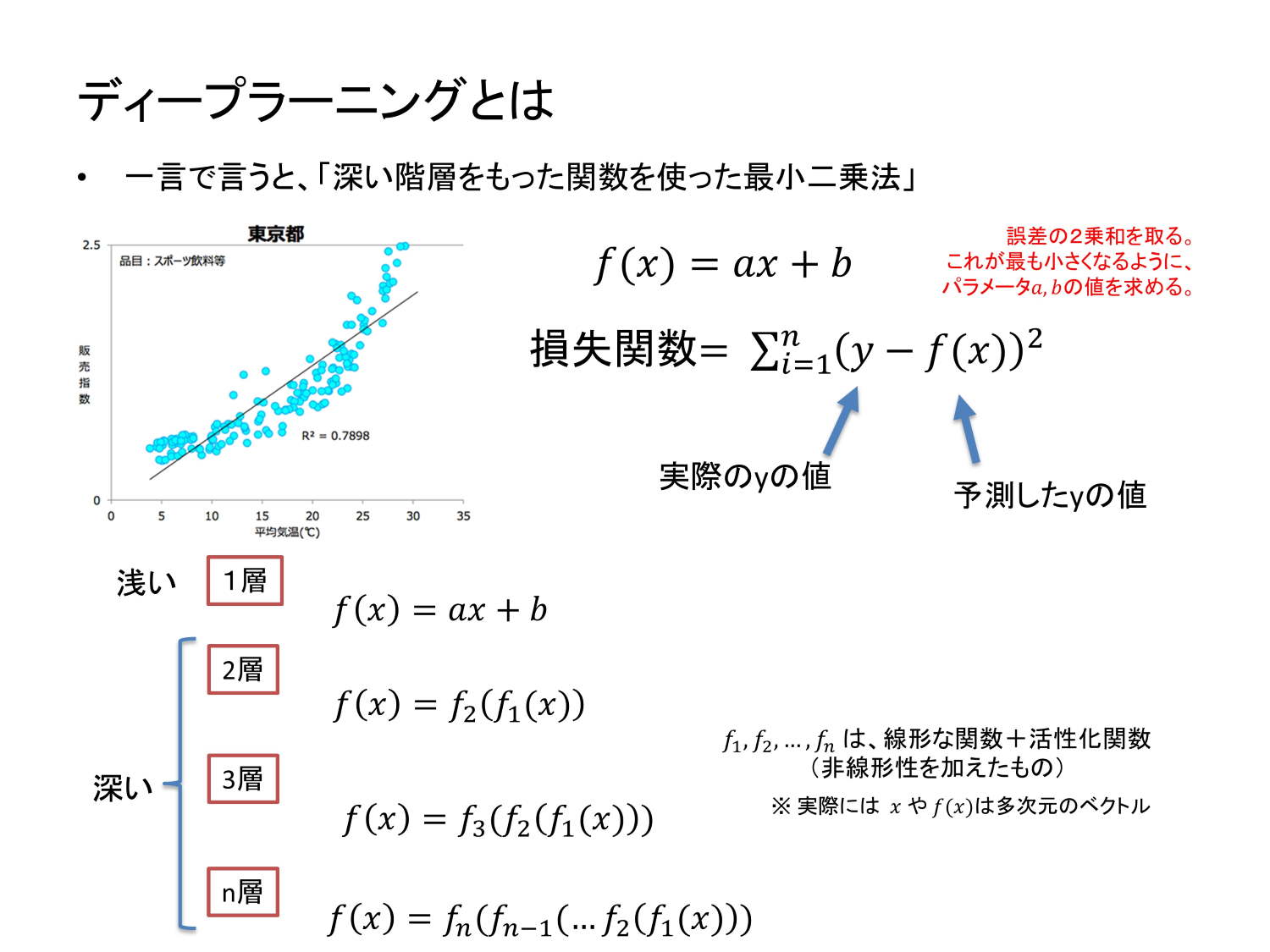
まず、「ディープラーニング」とは何かと言うと、非常に大雑把には、「深い階層を持った関数を使った最小二乗法」です。最小二乗法というのは、損失関数を定義して、それを最小化することによってパラメーターを求めます。
統計学を学んだ、比較的多くの方が何となく知っている概念ですので、それをベースにすると説明しやすいと思っています。これは統計の回帰分析と基本的には同じですが、使っている「関数が深い」というところが違います。
通常の最小二乗法をやるときには、線形関数や二次関数などを仮定しますが、これは「浅い」わけです。入力から1回だけ計算して出力されるからです。
ところが「深い」というのは、f1に入力した結果が、また別の関数f2に入って、また出ていきます。あるいは、f1に入れた結果がf2に入り、その結果がまたf3に入って出て行くというように、関数がネストされたようなものです。こういう関数を使って最小二乗法をやるというのがディープラーニングです。
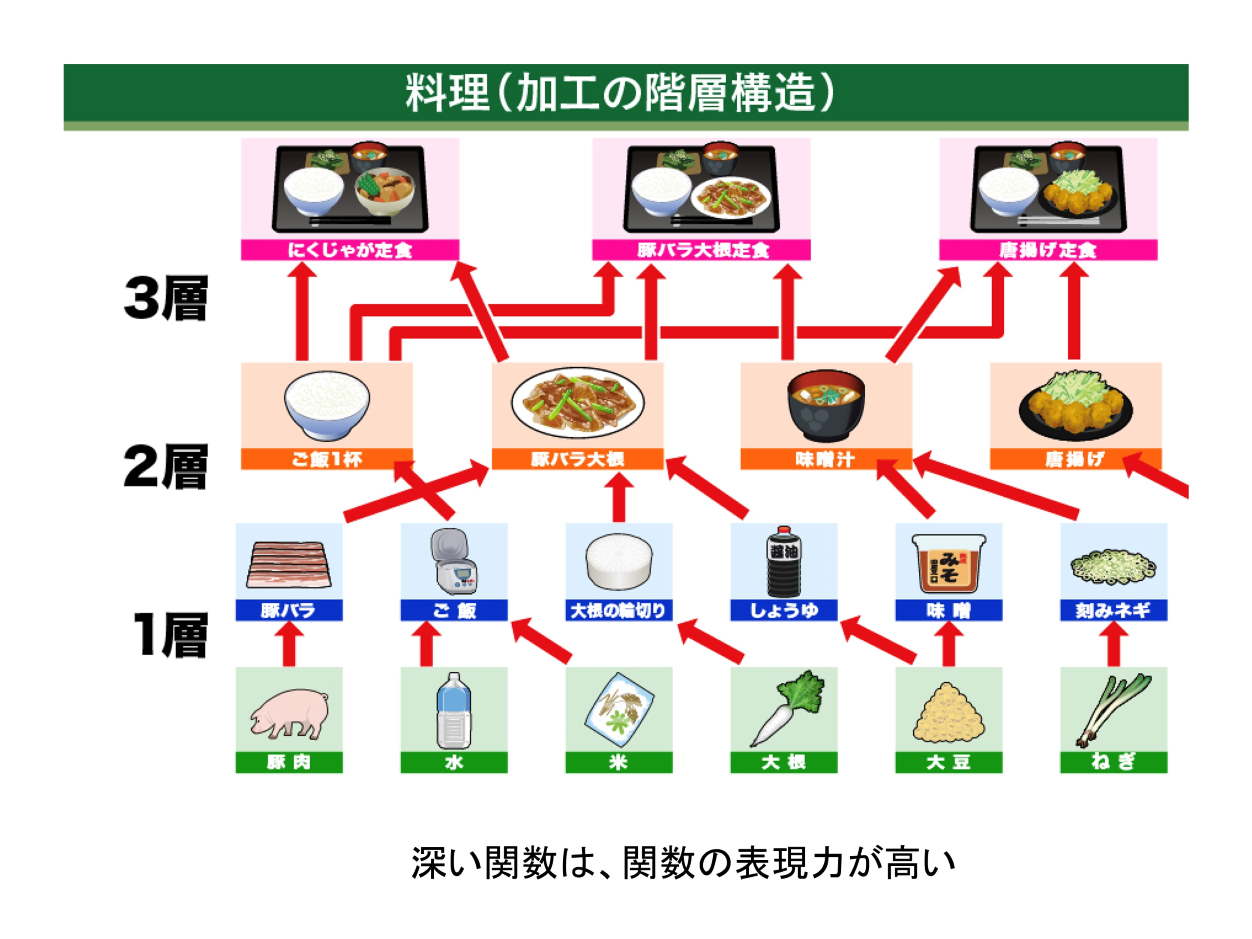
では、「深い」と何が良いのかを料理を例に考えましょう。
料理は食材を買ってきて、それを調理するんですが、一回だけ加工していいという条件で料理をするとどうなるでしょうか。水と米からご飯ができたり、ネギを刻んだり、それぐらいしかできません。ところが2回・3回・4回と加工していいとなると、その瞬間、ありとあらゆるものができちゃうわけです。
これは関数の場合も同じで、入力されてきたデータを一回だけ加工していいという条件の下で最小二乗法をやるのが従来の手法だったわけです。ところが関数が深くなると、2回・3回・4回と加工できることになり、いろんな加工が可能になります。料理でいえば、いろんなレシピが作れるようになります。
これを「関数の表現力が高い」といいます。深い関数は関数の表現力が圧倒的に高いというわけです。こういった関数を使った最小二乗法のようなことができるようになってきたのがディープラーニングの意義だと言えます。
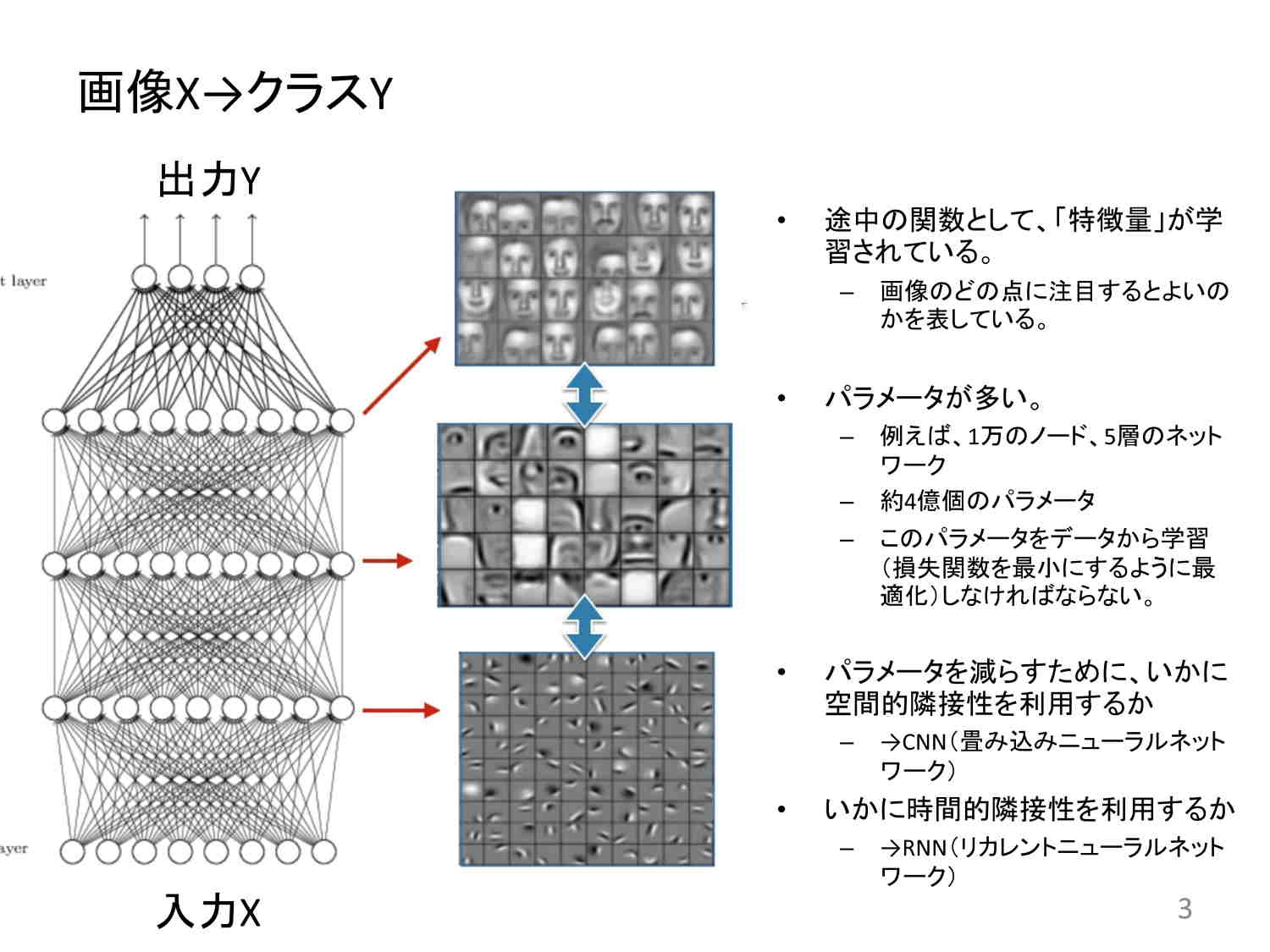
よく画像認識でこういう図が出ます。入力として画像を入れると、出力として画像のラベルを出す。ラベルというのは、「これは猫」「これは犬」といったことです。
この図では、4階層で4回ネストした関数を使って最小二乗法をやります。そうすると結果的に得られたものは、エッジの検出をしていたり、目や鼻のような顔のパーツを検出していたり、あるいは顔全体を検出していたりということが分かる。これを「特徴量を学習している」という言い方をします。
もちろん、こうした深い関数を使うことが重要だということは従来から重々わかっており、何十年も前から研究者たちはこういう手法を作りたいと思っていました。ところがパラメーターの数が多過ぎて、できなかったわけです。
図では、非常に線が混み合っています。この一つ一つが重みを表しています。例えば、入力のxが100×100の画像、つまり一万次元だとして、次のレイヤーも一万次元だとすると10,000×10,000で1億本のコネクションを持つということです。
これでは、パラメーターの数がとてつもなく多くなります。ですから、これを最適化するのが大変だったわけです。ところが、計算機のパワーが上がり、こういうディープラーニングの手法が可能になってきています。
これが顕著に効いてきたのが画像認識です。そのため、画像認識の精度が非常に上がってきました。こうして2012年からディープラーニング手法が使われるようになり、もう人間を大きく凌駕するようなところまで来ています。
これを使えば、動画の中に何があるのかも非常に正確に検出することができます。四角で囲んだ中のものが「人である」とか「椅子である」といった認識をすることもできるようになってきました。

こうした画像認識をロボット・アクチュエーター系と組み合わせると、例えば、物を掴んで元の場所に戻すような片付けロボット、イチゴを認識して上手く摘み取るイチゴの収穫ロボットなどができるわけです。また、無人の重機を自動操縦して、画像認識しながら上手に穴を掘っていくこともできます。
ディープラーニングは、画像を生成することもできます。例えば、犬、ハンバーガーといった学習データにはないような画像も、本物と見紛うような綺麗さで生成することができます。この技術がここ5年ぐらいで急速に進んでいます。これを「生成モデル」といいます。
機械学習の手法は大きく識別関数、識別モデル、生成モデルという3つに分類することができます。識別関数と識別モデルは比較的似ていて、あるデータxが与えられた時に、これがどのクラスに属するかという、その条件付き確率のxが与えられた時のカテゴリcの確率を求めるような方法のことをいいます。
一方、生成モデルというのは、データxとクラスcが同時に正規するような確率のモデル、同時確率というのをモデル化するものです。これは識別するクラスを分類するために使うこともできれば、異常検知に使うこともできます。また、データを生成するために使うこともできます。いろんな使い方ができるということです。
このディープラーニングによる生成モデルには、有名なものとしてGAN(敵対的生成ネットワーク)とVAE(変分オートエンコーダ)の2つあります。
GANは、例えていうと偽札を作る犯人と偽札を見破る銀行が競い合うことによって、両者とも精度が上がっていくようなものです。
犯人はできるだけ本物に近い偽札を作ろうとし、銀行は偽札と本物のお札をできるだけ見分けられるようするため、両者ともにレベルが上がり、どんどん本物に近い偽札が作られるようになってくるということです。これを発展させたDCGANとかBigGANができていて、非常に精度が上がってきています。

一方、VAEというのは、オートエンコーダのデータをもとに潜在変数zに圧縮して、それをまた元に戻すということをもう少し確率的にしっかりさせたものですが、これも同じようにいろいろな生成ができます。
さらに、条件付き(コンディショナル)GANとか、コンディショナルVAEと言われるものがあって、何らかの条件を付けた上での生成ができます。
例えば、顔画像を生成する時にメガネをかけたような顔画像を生成したいとか、男の人ではなくて女の人っぽい顔画像を生成したいとかいう条件を与えて、その下で生成するということができます。この条件付きの生成っていうのをうまく使うと非常に面白いことがいろいろできます。
これらをさらに進化させたものに、Cycle GANがあります。このCycle GANは、シマウマの画像を馬に変えたり、いろんな変化ができるんです。例えば、地図を実写に変えたものを再度実写から地図に戻します。この2回の生成をして戻ってきたものが一緒であるというような仮定を置いた上で、生成と識別を学習していくものです。 サイクルになっているのでCycle GANといいます。
Cycle GANですと、画像のペアが不要です。シマウマの画像とか馬の画像がたくさんあれば、こっちからこっちを生成し、こっちからそっちを生成しという学習ができるので、応用の可能性が広がります。いずれにしても、条件をつけて、いろいろな画像の生成ができるようになってきたということです。

一方で、いろんなものを上手につかめるロボットや重機の自動操縦などが研究されています。ここには、強化学習という技術を使っています。ロボットが作業を続けていくうちに、だんだんと上手くなります。強化学習には、モデルベース強化学習とモデルフリー強化学習の2種類があります。
モデルベース強化学習は、ある状態のときに何らかの行動をすると次にどういう状態になるかという遷移が、明示的に定義されているものです。囲碁などは、ある状況から自分がこういう手を打つと次の状態がどうなるかが一意に決まります。こういうものをモデルベース強化学習といいます。
モデルフリー強化学習はある状態から何らかのアクションをすると、次にどのような状態になるのかという明示的なモデルを持っていません。例えばAtariのゲームの学習は、次に何が起こるかという明示的なモデルを持っていません。一度やってみたらうまくいくと分かると、前の状態に遡って、こういう状態は良い状態だと学習していくわけです。
人間の場合は、ある状態から何かをしたときに、次に何がどういう状態になるかということが普通分かっています。そういう遷移についても人間は学習しているんです。
ですから、モデルベースなのかモデルフリーなのかという議論ではなくて、このモデル自体を人間の場合は学習し、それを使ってモデルベース強化学習をしているという解釈が正しいんだろうと思います。これを世界モデルと言います。このあたりの研究が盛んになってきていています。世界モデル、メタ学習、ドメイン適応などが関連した概念です。
元々これらに近いものは研究されていました。2017年の研究を紹介します。
例えば、画面の中でビリヤードの球が動いているように見えます。通常、ビリヤードの球が動く様子を見せるには、ニュートン方程式を使って、あるいは摩擦を表すような摩擦係数を使って、転がる様子を描きます。
そうではなく、ビリヤードが転がる様子をひたすらディープラーニングで学習させて、こう動くはずだというモデルをCNN、LSTMでつくります。こうすることで、球の動きを上手に予測できるようになるという例です。ビリヤードの球が動くようなフレームのデータ(動画)をたくさん学習させるだけで、予測できるようになるわけです。
2016年の別の研究には、Deep Predictive Codingがあります。 次のフレーム、次の次のフレームで何が見えるかを予測するモデルです。動画を見るとき、人はおそらく次にこういうのを見るだろうと予測しています。
例えば車から見える景色が流れて行くのをずっと見ていると、人は次に何が見えるかを予測しながら見るわけです。実際のフレームと予測したフレームがほぼ同じになるようなモデルが作られています。こうした手法を使って、次のフレーム、次の次のフレームに何が見えるかを予測することができるようになってきています。

こちらはロボット使った別の研究です。ここではロボットを使って、自分が手を動かすと何が起きるかを予測しています。
上側が実際の様子で、下側が予測したものです。たくさんのものがあるところで手を動かすと物が動くだろうとか、何もないところで動かしても何も起こらないだろう、というのが予測できるようになっています。
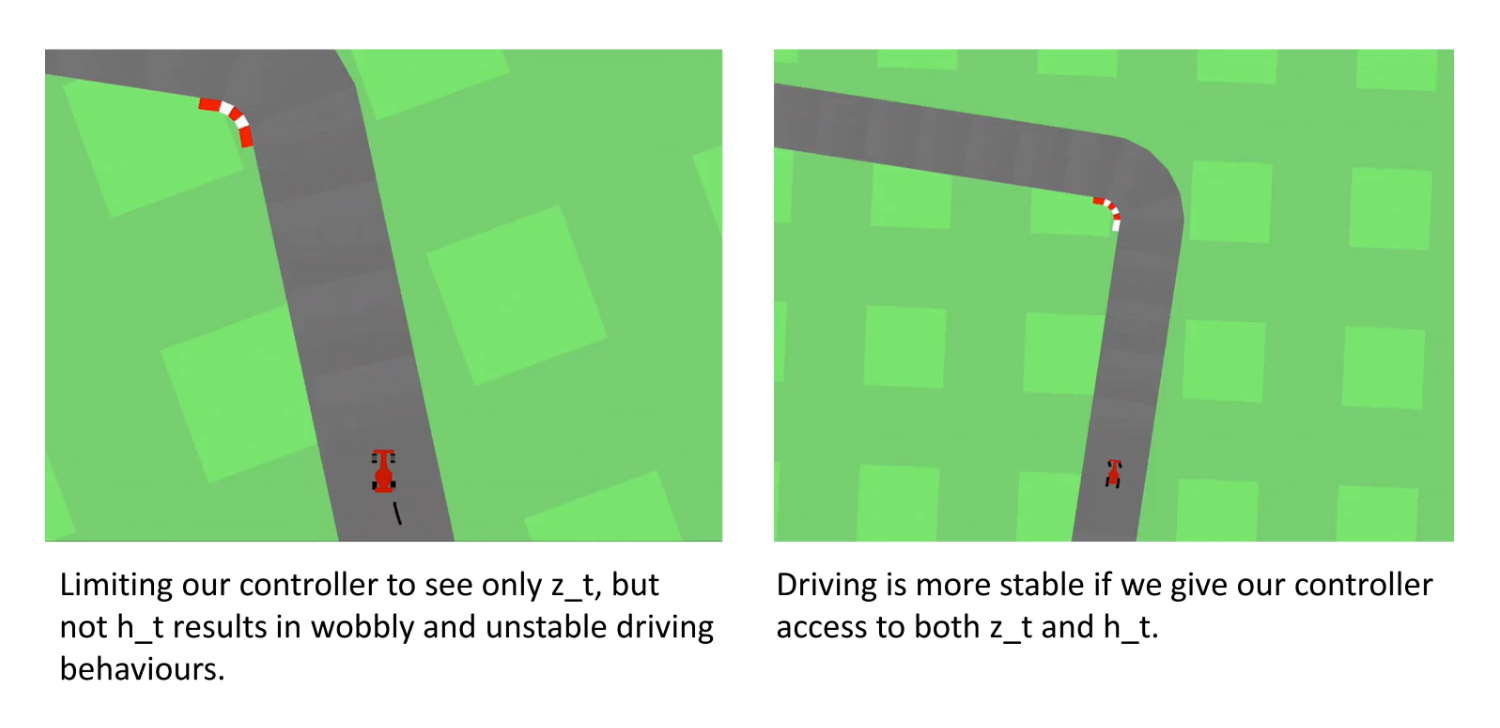
また昨年、world modelsという研究が出ました。先ほどの世界モデルの研究です。ここでは、二次元のゲームにおいて、次のフレーム、次の次のフレームで何が見えるかという予測をモデル化しています。車が一番うまく進めるようにハンドルを切って、非常にスムーズに運転ができるようになるというような研究です。
さらに昨年、Deep MindからGQN(Generative Query Network)という研究が出ています。これも世界モデルの研究で、ある物体をこの視点から見るとこういう画像が見える、では別の視点から見るとどういう画像が見えるのかという予測問題をたくさん解かせます。
こうすることで、室内の物体を表すような三次元の内部表現を自動的に獲得できるというような研究です。これらから分かるのは、現実の空間を表すような表現を獲得したり、近い未来に何が起こるかを深層生成モデルを使って予測したりといったことができるようになってきたということです。
ここで、ようやく言葉の話が出てきます。これもヒントになるような研究が2つほどあります。
一つはAutomated Image Captioning(キャプション生成)です。
画像を見て、キャプションを生成する技術です。認識した画像の内容を表すようなベクトルをLSTMの初期値として持たせて単語を生成していきます。このとき、画像とキャプションのペアが大量に与えられているため、この画像に対しては、こういうキャプションを生成するということがわかっています。
これらの誤差を計算し、その誤差を逆伝播で戻してパラメーターを調整していくものです。また、逆にキャプション(文字)から画像を生成することもできます。また、一度生成した画像の未来を予測するということもできるようになっています。

ここから先、技術が進展すれば、言葉の意味処理が本当に可能になってくると思います。ここで、そもそも意味とはいったい何でしょうか。
いろいろな研究がこれまでずっとありますし、いろんな議論があるのであまり迂闊なことは言えないのですが、非常に大雑把に言うと、原始的な意味とは「ある言葉を見た時に脳神経回路内に再現される絵である」ということではないかと思っています。この意味では、先ほどのキャプションからの画像生成は、もう結構近いところまでできています。
ところが人間が考える意味というのは、もっともっと深いことも指します。静止した画像ではなく、時間的な発展を伴うような概念です。また、視覚だけとは限りません。目で見る以外に、例えば馬のいななきとか、触った感じなどの五感の情報を含めて再現しています。そして、センサだけに限りません。手や足を動かすアクチュエータの出力も再現します。
こうした何らかの概念が脳内に再現されているわけです。とはいえ、一番ベースとなるのは、言葉から絵を生成するということであり、それだけであれば、かなりの部分がもう現状の技術でできていると思っています。
ここで、少し人工知能の歴史を振り返ります。人工知能は1956年からずっと研究されているわけですが、シンボル派とパターン派の戦いが続いてきました。
昔の研究者にはシンボル派の人が多く、人間の知能というのは記号操作であり、シンボルマニピュレーションの力が知能の根源だと言ってきました。一方で、ディープラーニングの話はパターン派にあたります。この二つがどのような関係にあるのかです。
人間も動物なので環境中の情報を知覚し、それによって適応的な行動するということをやっています。ここは完全にパターンの世界です。今、ディープラーニングで行っている画像認識やロボットが上手に動けるといったことは、基本的には動物と一緒でパターン処理がうまくできるようになったということに由来します。この仕組みをベースに、この上に人間は言葉の処理、記号の処理を載せています。
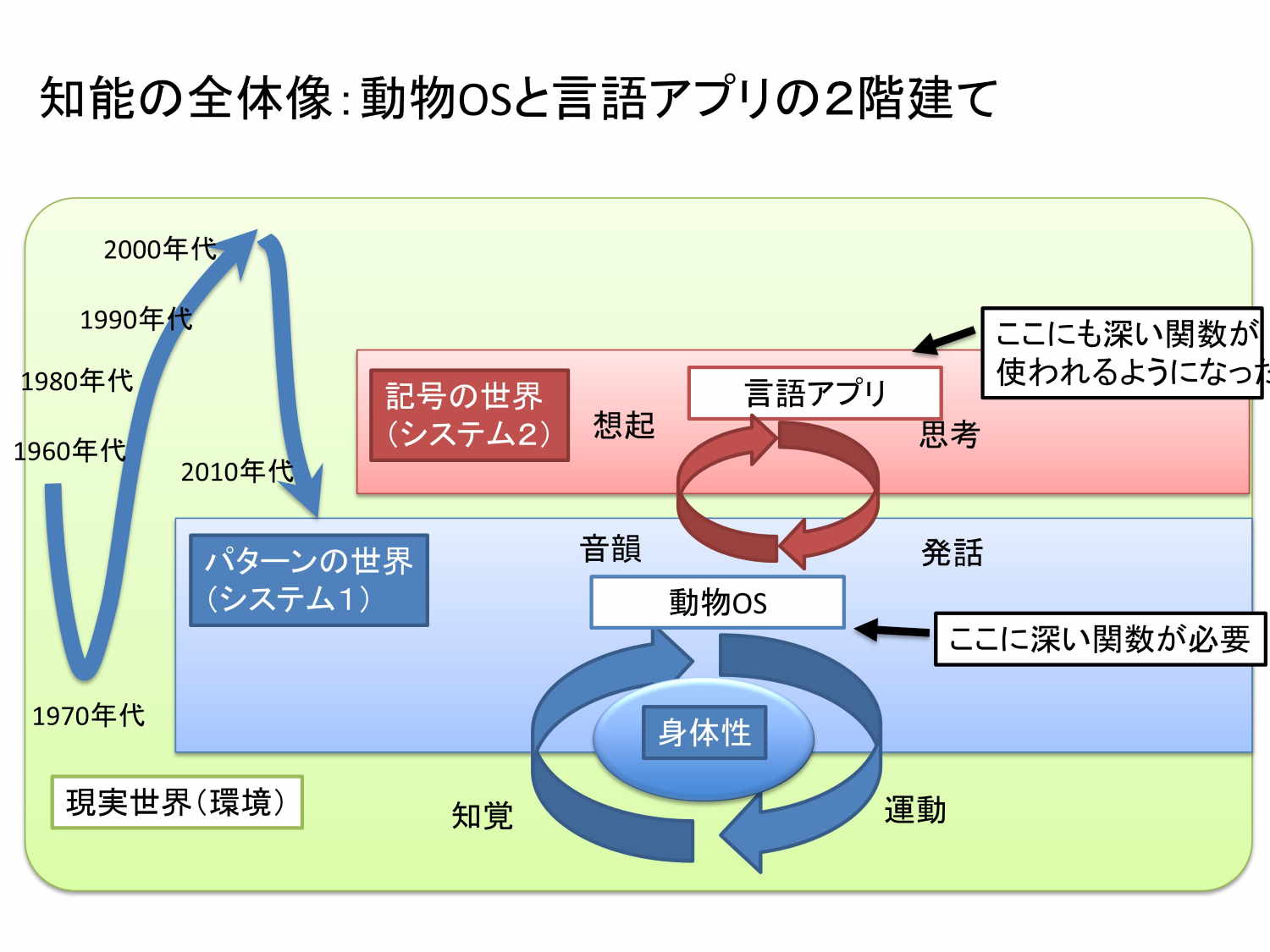
つまり、一階部分が知覚運動系、二階部分が記号運動系という二階建てになっています。最近は、一階部分を「動物OS」、二階部分を「言語アプリ」と呼んだ方がわかりやすいかなとも思っています。
動物OSとして、人間には高等な哺乳類とほとんど同じOSが入っていて、バージョンもほとんど同じです(笑)。一方、言語アプリとしては、人間特有のものが入っています。言語アプリがあるからこそ、人間の知能は特異的なのだと思います。
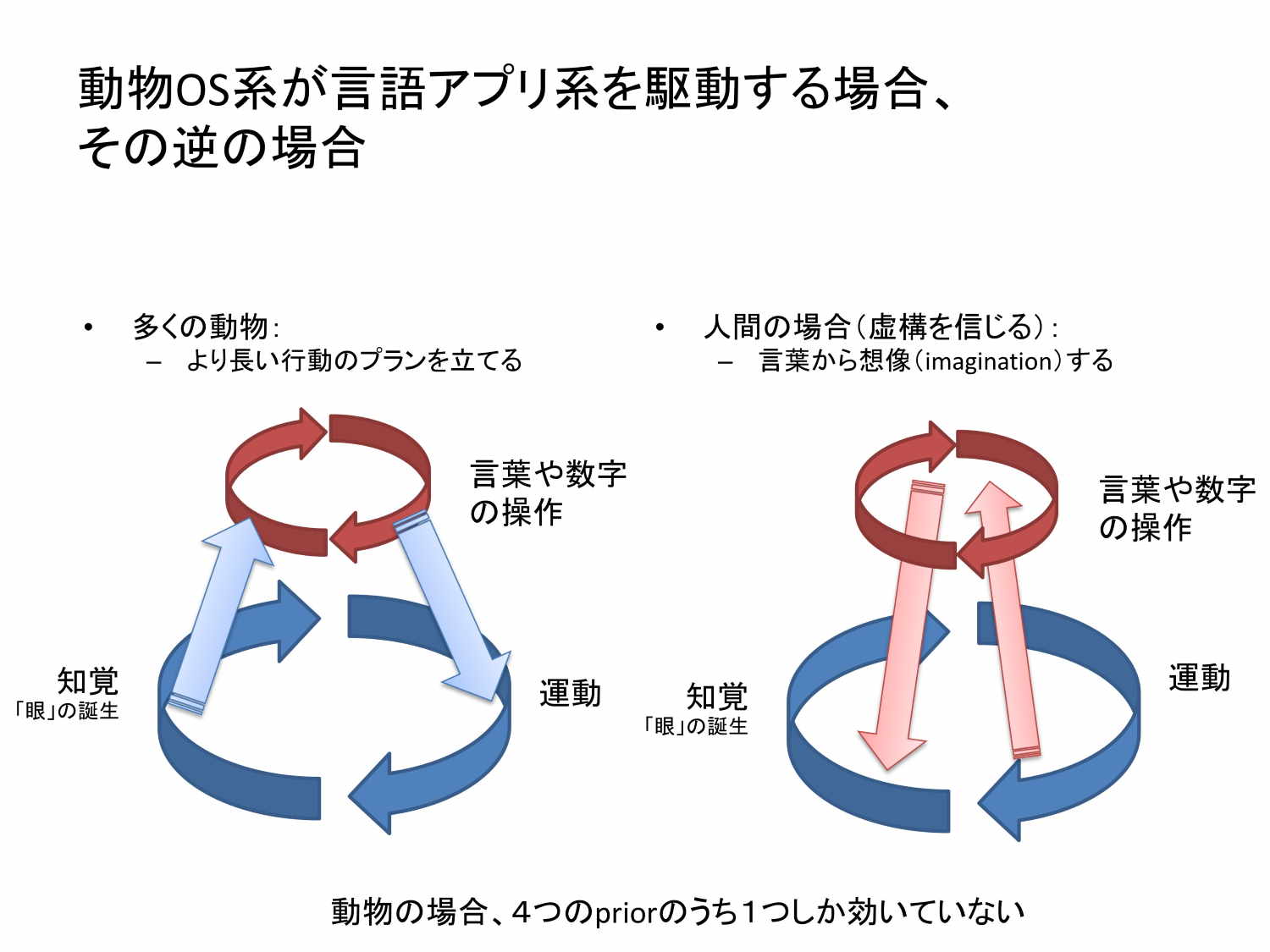
人間の言語アプリでは、「言語アプリ」が「動物OS」をAPI的に呼び出すということやっています。他の動物は、より長期のプランを立てるために「動物OS」が「言語アプリ(の原始的なもの)」を呼び出すことをやるんだけども、人間の場合は、「言語アプリ」が「動物OS」を呼び出すわけです。これは「目の前にない状況を言葉から整理する」ということです。
例えば、「大きなリンゴの木がありました」と言うと、皆さんの頭の中に大きなリンゴの木が描かれます。「そこに猿がやってきました」と言うと、猿が描かれる。「では猿は何をしたんでしょう?」と聞くと、「猿はリンゴの木に登ってりんごを食べたんじゃないですか」と言えるわけです。
このプロセスでは、言葉から絵を描く、絵を足す、そして絵を動してみるということによって、結果的に猿がりんごを食べたんじゃないかということを言っているわけです。これが意味理解です。
目の前に猿はいないし、りんごの木もないんだけども、言葉からそれと同じような状況を作り出し、その状況をシミュレートして、また言葉に戻すということをやっています。この技術は先ほどお話ししたような技術でほぼできているわけです。まだまだ今いろんな課題がありますが、まだ統一的な形でできていないだけで、技術的なパーツとしてはかなり揃っていると思います。
特に人間の場合だけ、なぜ二階部分が一階部分を呼び出すような構造になったのでしょうか。おそらく書籍『サピエンス全史』に書かれているように「虚構を信じる」ということが、生存確率を上げたというかなりニッチな進化を遂げてきたためでしょう。
通常、生物にとっては現実世界が一番大事です。目の前にあるものに従事するのは当然で、目の前にないものを脳内の別の刺激によって作り出すということは、非常に危険な行為のはずです。
ところがそれを敢えてやるようになったのは、集団として結束するために「あのグループは敵だ」とか、「守るべきもののために戦う」といった意識を共有することで、結果的に集団全体の生存確率を上げることにつながったのだろうと思われるわけです。
二階建ての知能の構造を仮定することによって、従来から言われているいろんな哲学的な問題とか議論を整理することができます。
例えば、チューリングテストに対して、ジョン・サールは「中国語の部屋」という例で反論しました。大きな辞書を引いて中国語を返すことは、意味理解していることにはならないのではという主張です。
サールが言っていることを言い換えると、「言語アプリ」だけの処理では意味理解になっていない。「言語アプリ」と「動物OS」の両方が動くということが意味理解なんじゃないかということで、それは正しいわけです。
また、チョムスキーが「Colorless green ideas sleep furiously」という非常に有名な言葉を残しました。これは「色のない緑のアイデアが激しく眠る」という意味の分からない文ですが、文法的には正しい。文法的には正しいんだけども、ナンセンスな文体がなぜ存在するのかということを問うたわけです。
これも答えは簡単で「言語アプリ」が「動物OS」をAPIで呼び出した時に何も返ってこない、nullが返ってきてしまう。こういう状況を「動物OS」側が学習してないので、「生成モデルとして何も出せません」ということを言っているだけだと思います。

そう考えると、実は人間の言葉の処理とか理解については、いろんな整理をすることができます。よく我々が何か「理解した」「分かった」というのはたいていの場合、「言語アプリ」にとっての再現可能性のことを指していて、「言語アプリ」は要するに脳内に絵を書いていくんです。シーケンシャルに絵を書いていく装置であって、それがいつも同じ書き方をすればいつも同じ絵になるということが分かれば、我々は分かったといいます。
ある数式を展開するとか、ある小説を読むとか、ある手順を遂行するということを同じことを同じやり方でやれば必ず同じ結果が出るということが担保されていると、この「言語アプリ」の側が「わかった」「理解した」ということだろうと。
ですから、人間が言葉の意味が分かるとか、指示を理解するとかいうことも同じです。この「言語アプリ」のほうが「動物OS」を通して、いつも同じようなメンタルな状態を作り出すことができると「文の意味をわかった」ことになるということだと思います。
今のディープラーニングの自然言語処理は、いずれもこの「動物OS」がないんですね。「動物OS」を欠いた状態で「言語アプリ」だけで処理を行っても精度が上がるはずがないと思っています。それにもかかわらず、人間並みの質問応答や翻訳の精度が出ていること自体はすごいです。
ただ、人間がとても読めないぐらいのデータを使って、ようやく人間並の精度しか出ていないとも言えます。やはり、それではやり方がおかしいというのは間違いない。「動物OS」がないからです。それは、言葉が「動物OS」の画像、動画などを生成するような仕組みを備えた言語処理のアルゴリズムができれば、僕は本当の意味で「意味が分かった」「意味を処理している」ということになると思っています。
それは、言葉が「動物OS」の画像、動画などを生成するような仕組みを備えた言語処理のアルゴリズムができれば、僕は本当の意味で「意味が分かった」「意味を処理している」ということになると思っています。
現在の感覚としては、パーツは揃っていますし、精度をあげようと世界中の研究者が一生懸命やっています。かなり近い将来に、技術的にできるレベルに達します。そうすると言葉から脳内の状況をうまく再現するような技術ができるので、本当の意味処理ができる。

意味処理ができると、かなり大きなことが起こると思っています。
今のコミュニケーション技術は「意味が分からない」「処理できない」という前提の中で、パターンをうまく使って何とか対話的なことをするとか、タスクを処理するということをやっています。この技術は、それはそれですごいですが、本質的にはまだまだ重要なところを解決していません。
これを解決できると、本当にメールや対話で指示ができ、調べたことを言葉で返してくれるような処理がいろいろと可能になってきます。世界に非常に大きな変化を生むんじゃないかなと思っています。
今日は特にコミュニケーションを中心にお話ししました。
本当に言葉を扱うような、コミュニケーションの技術は、ここから何年かわかりませんけども、非常に大きく変わる可能性があります。
その時に、その技術をどこが作るのか、オープンな形で提供されるのか、それをビジネスにつなげて行くにはどうしたらいいか、各企業の中でどういう風に活用ができるのか、こうしたことが非常に重要な論点になってくると思っています。
ご清聴ありがとうございました。
Communication Tech Conference2021開催決定
2021年2月26日(金)13時~『Communication Tech Conference 2021』を開催します。
下記バナーより特設サイトをご覧いただきます!

「テクノロジーは、人々のコミュニケーションをどう変えていくか」をテーマに、今回で3回目の開催となるカンファレンスです。なお、新型コロナウイルス感染症の拡大防止の観点から、初のオンライン形式で実施予定です。
新型コロナにより暮らしや働き方、それに伴うコミュニケーションが一変した中、テクノロジーはどのような進化を遂げているか。
特別ゲストに、Zoom創業者のエリック・ユアン氏、基調講演にソフトバンク社長 宮内謙氏の登壇が決定しました。また、ソフトバンク社によるテクノロジーデモセッションや、LINE社などによるトークセッションを行います。
さらに、「Work Style(働き方)」、「Customer Support(顧客サポート)」、「Entertainment(エンターテインメント)」をキーワードに、各分野を牽引する企業が登壇予定です。
この機会をぜひご活用ください。