chatGPT3等の自然言語処理(NLP)を用いた顧客サポート現場での活用方法をご紹介
投稿日:2023年2月8日 | 更新日:2025年3月3日

<2021年5月26日⇒2023年2月8日更新>
2023年1月現在、OpenAIが2022年11月に公開したチャットボット、ChatGPTが世界的に話題を呼んでいます。
OpenAIによるGPT-3.5ファミリーの言語モデルをベースに構築されているChatGPTですが、今回のコラムでは過去の記事をもとに、そもそもGPTなどの自然言語処理(NLP)モデルの進化全体や、カスタマーサポートとの関わりについて整理しながら、このGPTモデルについても改めて解説をしていってみたいと思います。
実は、自然言語処理(NLP)については、分かるようで分からない方も多いのではないでしょうか。今起きている自然言語処理の進化と、実際の顧客サポート現場での活用のされ方について今一度整理をしてみましょう。
ChatGTPは業務で使われているのか?
業務でのChatGPT利用動向調査レポートを無料で公開中!
そもそも自然言語処理とは何?
自然言語処理(Natural Language Processing=NLP)とは、人間が互いのコミュニケーションを行うために自然に発生した言語、例えば日本語や英語などの「自然言語」と、自然言語をコンピューターに理解・処理させる一連の技術を意味する「処理」を組み合わせた言葉です。
顧客サポート現場ではチャットボットや言語翻訳、テキスト分類や分析、感情分析などの用途で使われている技術です。
自然言語処理の歴史は実は長く、20世紀初頭までさかのぼることができます。初期は1900年代に確率論や統計学の研究から始まりましたが、2000年代にはコンピューターの登場で、より大量のデータを使いながら性能向上や統計的手法の用途で活用されています。
そして、2010年代の第3次AIブームと呼ばれる時期から、ディープラーニングやニューラルネットワークによって飛躍的に発展してきました。
2010年以降のNLPの進化
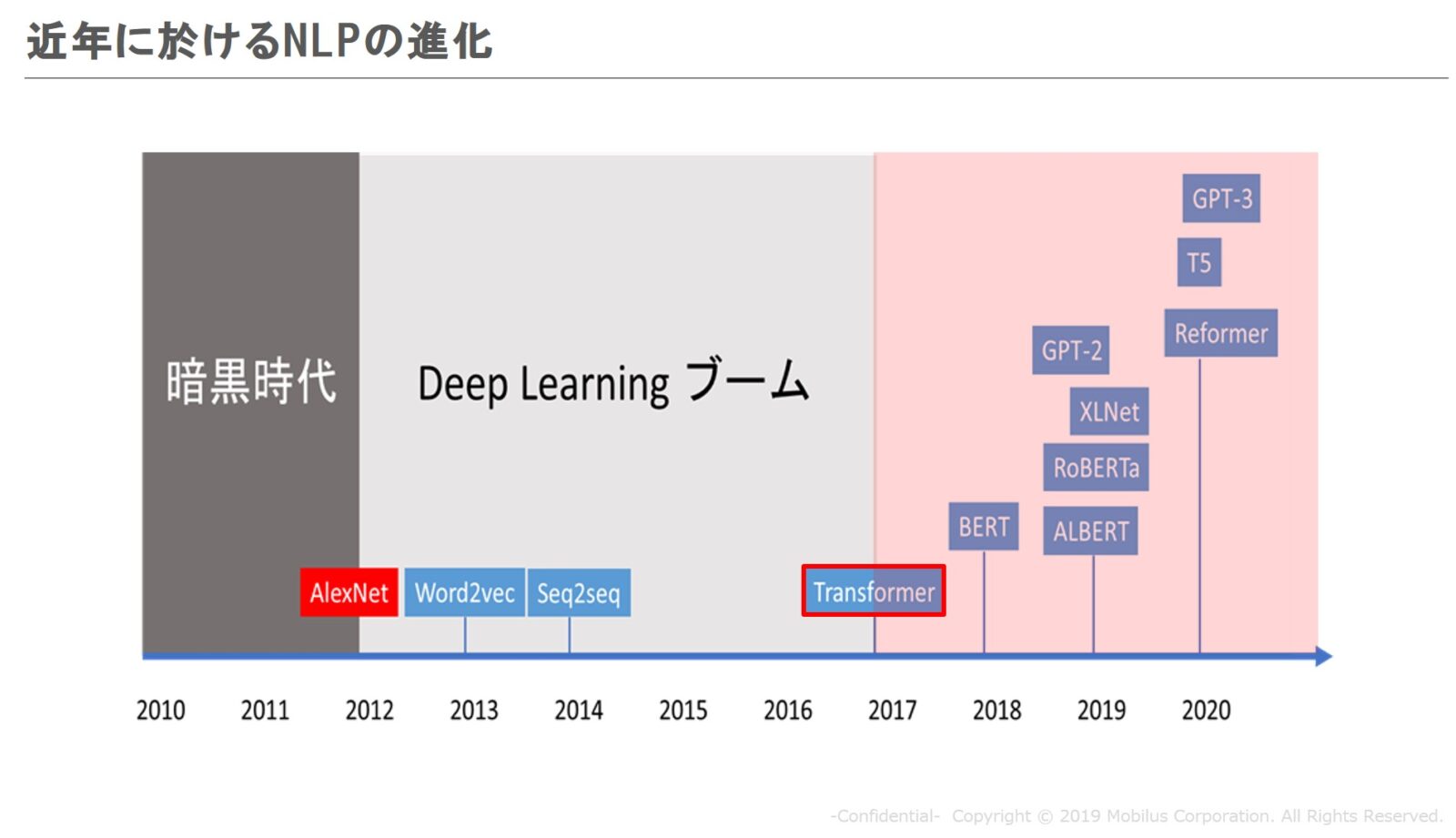
NLPモデルが急速に進化を始めたのがディープラーニングのフレームワークが活用され始めた2011年後半です。そして、2017年に出てきたTransformerが一つの契機になって発展のスピードがさらに上がったと言われています。
一説ではAIの活用における画像認識や音声認識の研究が先行して進み、それがひと段落したこの2017年前後の時期に、NLPにリソースが注がれるようになったという話もあります(※諸説あり)。
それぐらいインパクトがあると言われているのがTransformerモデルであり、その後「Transformerの進化系」として、BERTやGPTといった派生モデルが出現しています。
コンタクトセンター業界でのNLP活用の現在地
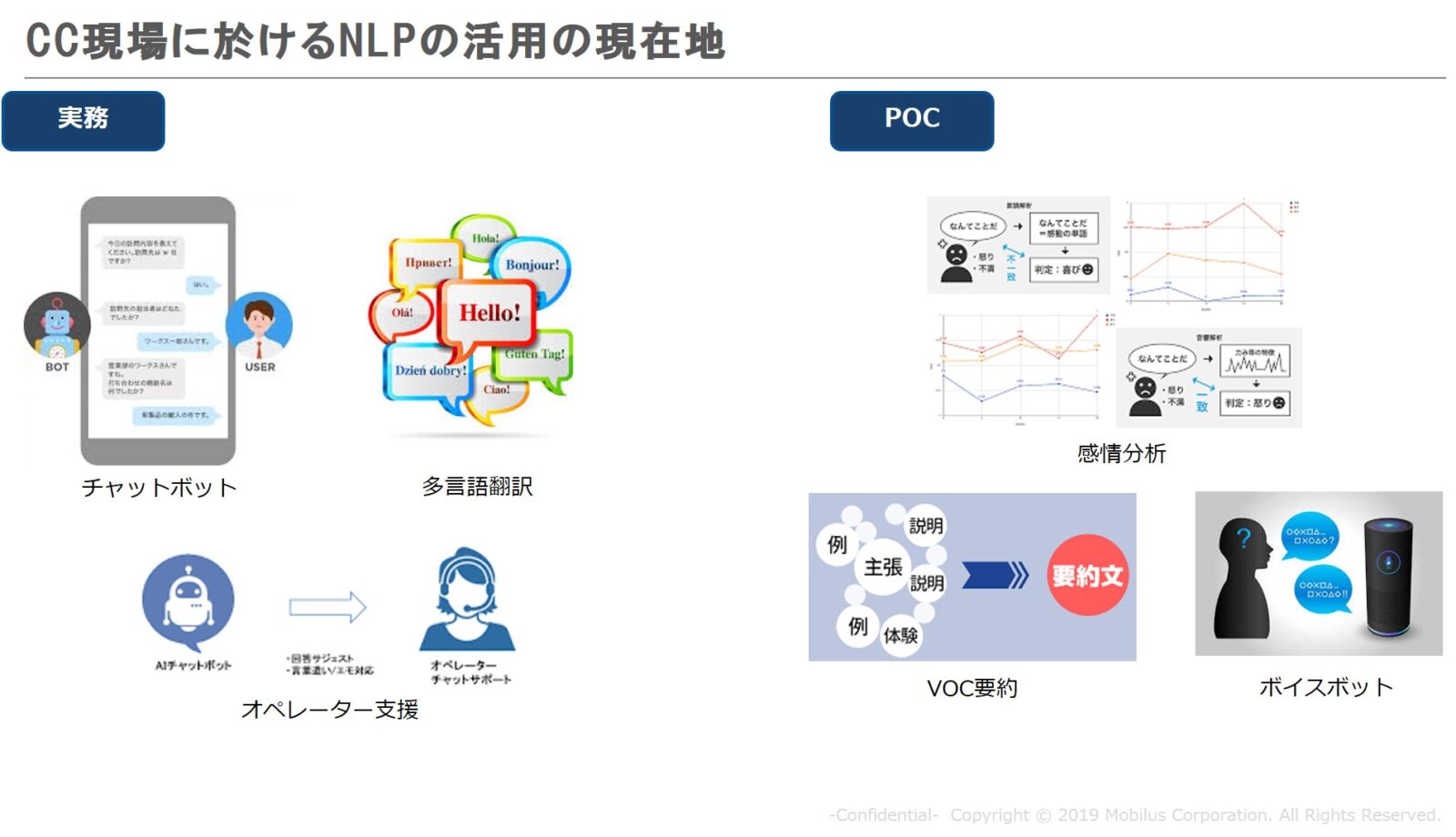
さて、顧客サポート、コンタクトセンターの分野でNLPはどのように使われているのでしょうか。
実務ベースとしては、顧客からの問い合わせを自動で答えるチャットボットやオペレーター支援として多言語翻訳、回答文章の提案のシーンなどで使われています。まだPOC的な色合いは強いですが、「チャットの感情分析」や「コンタクトセンターのログの解析・分析、大量のやりとりを分析するVOC要約」、「テキストではなく音声で電話を介在して店舗の予約をするボイスボット」などでの利用が徐々に始まっています。
現在の「チャットボット」の分類整理
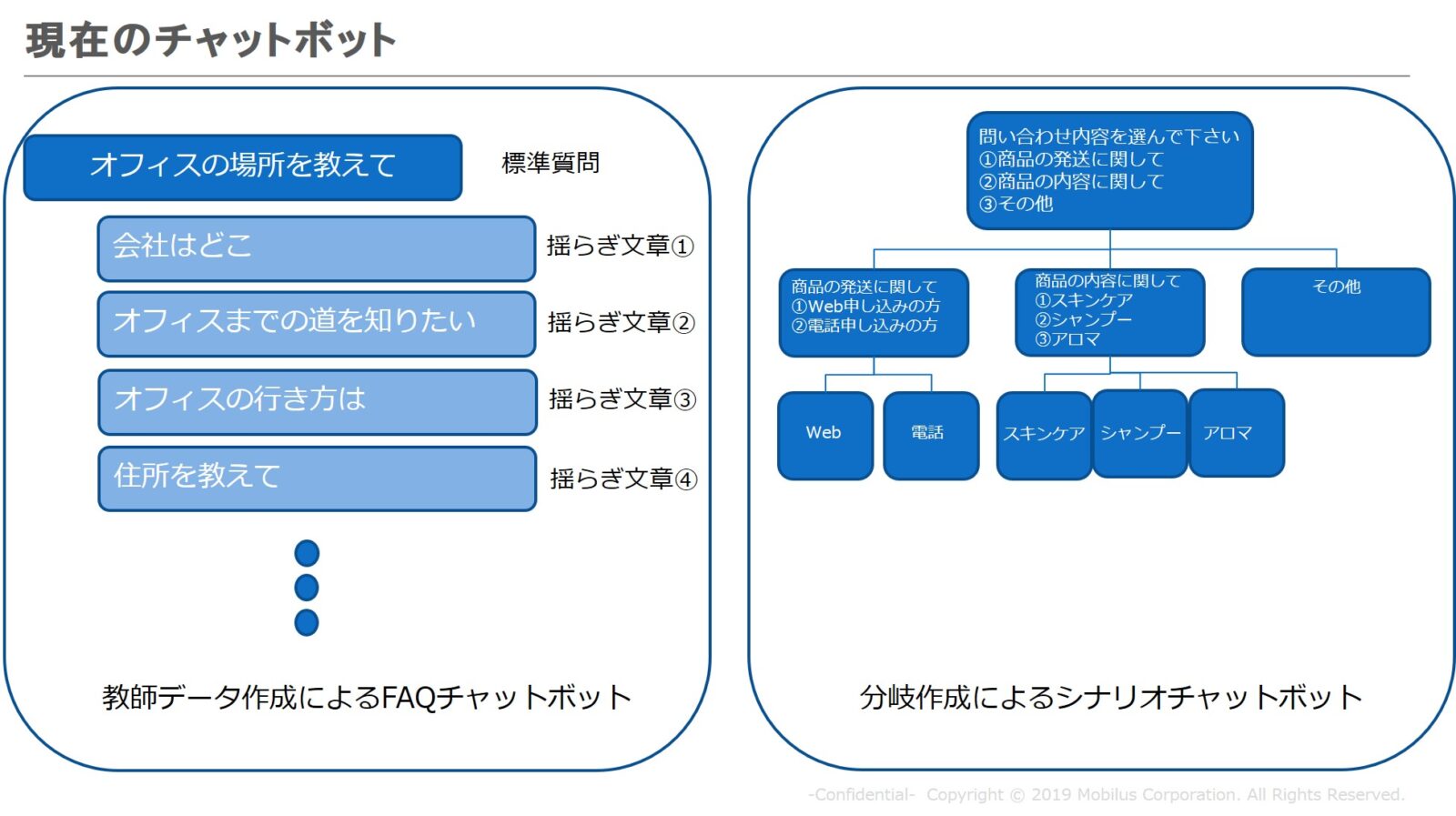
現在のチャットボットは、簡単に言うと二つに分類されます。まず「一問一答型」と呼ばれるものです。何かを自然文で聞いたらその問いかけに対して答えてくれるのが一問一答型、つまり、「教師データ作成によるFAQチャットボット」です。
例えば、「オフィスの場所を教えて」という質問に関して、「会社はどこ?」「オフィスの行き方は?」といった表現の揺らぎの文章をいくつか学習させます。自然な言語でこのような様々な表現で入ってきた質問にも回答できるように、学習データを改善しながら回答率を挙げるようにしていくタイプのものになります。
もう一つは、「分岐作成によるシナリオチャットボット」です。こちらはAIというよりは、樹形図で表せるような選択肢を選んでいくことで答えにたどり着くというものになります。
「一問一答ボット」と「シナリオボット」。大きくはこの二つの組み合わせで、企業のサポートページなどにチャットボットは活用されています。
これらは現状は、FAQ(よくある質問集)の一つの表示形式として使われることが多いです。FAQのほかには手続き業務の自動化としてチャットボットが使われています。ただし、NLPの進化でこれらは今後どのように進化していくのでしょうか?
GPT-XXとその先の言語モデルの威力
上記のNLPの進化の後半にあったGPTという言語モデルを聞いたことのある方もいらっしゃると思います。Transformer以降に発達してきたこの自然言語モデルを活用するとどのような世界になっていくのか、動画事例と一緒に見ていきましょう。
【事例1】プログラミングコードの自動生成

お問い合わせ・ご相談フォーム
関連外部サイト
トランス・コスモスが運営する情報サイト「Cotra」
AIチャットボットとは?導入目的や3つのメリットを解説
コールセンターのAI活用とは?メリット・デメリットや導入例を解説